Whenever discussing CPU-bound performance (at least in the last 10-15 years) CPU cache is almost always a dominant factor. However often people say "oh probably cache" when explaining away some observation. They’re probably right, but let’s dive a little deeper into how exactly a modern CPU cache (or caches) works.
We’re going to learn how to unpack jargon such as:
-
Level 1 32KB i-cache and 32KB d-cache, 8-way set associative,
-
Shared level 3 8MB cache.
And also talk about cache behaviour in multi-processor systems as well as another type of cache called a TLB.
I’m working on a set of articles that are going to deal with cache effects, and wanted to start with this background information, not all of it will be needed but all of it is interesting (or tedious, depends on how tightly wound your propeller-hat is).
I’m going to assume you already know that cache is a type of fast memory that is "nearer" to the processor and so communication with it is faster with lower latency. That it holds copies of some things from regular memory to speed up program execution, because programs will tend to access memory near memory they’ve already accessed recently.
While I write this I was checking my knowledge with some web searching. I found that there are plenty of other resources online including worked examples. But I thought I’d summarise it anyway.
Cache levels
I remember owning a 486 motherboard that had an extra slot, next to the CPU that someone told me was for "cache". I found a circuit board that fitted there but I never tested to see if it made a difference. Point is that when the slot was empty, or if your 486 motherboard didn’t have it, it had 0 levels of cache. When you put the right card in that slot, then you had "one level of cache".
I mis-remembered, and just started reading the Game Design Black Book: Doom (which looks great! so excited!): The 486 has an integrated L1 cache and the slots/sockets available on motherboards are for L2.
My i7 Desktop has 3 levels of cache. The neat hwloc-ls tool on Linux will show you something like:

Package L#0 + L3 L#0 (8192KB)
L2 L#0 (256KB) + L1d L#0 (32KB) + L1i L#0 (32KB) + Core L#0
PU L#0 (P#0)
PU L#1 (P#4)
L2 L#1 (256KB) + L1d L#1 (32KB) + L1i L#1 (32KB) + Core L#1
PU L#2 (P#1)
PU L#3 (P#5)
L2 L#2 (256KB) + L1d L#2 (32KB) + L1i L#2 (32KB) + Core L#2
PU L#4 (P#2)
PU L#5 (P#6)
L2 L#3 (256KB) + L1d L#3 (32KB) + L1i L#3 (32KB) + Core L#3
PU L#6 (P#3)
PU L#7 (P#7)I have four cores, two processing units (PU) in each, and three levels of cache. Each core has three types of cache: L1d (level 1 data), L1i (level 1 instruction), both 32KB large, and a 256KB L2 (instructions and data). The package (that’s what you’re holding when you’re installing a CPU) itself has another level of cache (L3) shared between all four cores.
Cache is expensive memory, and the faster you need it the more expensive it is. It’s common to arrange it in levels, with the most expensive fastest cache memory nearest (or inside) the core. That’s our L1i and L1d. Because it’s expensive there’s only 64KB of it per core. We can afford 8MB of the least expensive cache (but still expensive relative to main memory).
Since this is a multi-processor we notice that if there’s only a single thread running it can use only its cores' 64KB and 256KB of L1 and L2. But it can use the whole 8MB of L3. When tasks run on other threads they share this 8MB (with whatever policy the CPU chooses). if some threads access the same data, they benefit by communicating through this shared last-level cache. There’s another term you may encounter: last-level cache (LLC) it’s whatever cache is furthest from the processor.
The other thing going on here is that the L1 is split between instructions (code) and data. There’s probably a good reason for that, it may be because code and data are typically fetched through different pathways and that code is almost always read-only. But those are just my guesses.
Cache lines
Cache is arranged in lines. Let’s see ask /proc/cpuinfo:
clflush size : 64
cache_alignment : 64That’s not exactly the answer for the question I was asking, but it’s close enough for jazz. Also I happen to know based on other sources. This CPU has 64-byte cache lines.
In other words, the cache manages 64-byte long (and aligned) blocks, or lines of memory. Managing cache in lines improves its use, since if you read the first word from a line, you’re likely to read following ones and now they’re hot in your cache (words are 8 bytes (64-bits) long on a 64bit system). Larger cache lines reduce bookkeeping costs since the CPU will keep data per-line. However large lines will also reduce how well the cache can handle random access workloads.
Cache associativity
When a CPU wishes to retrieve some memory it asks the cache; if the cache is 8MB and contains lines of 64 bytes each, then the CPU needs to know which of the 131,072 cache lines to check.
The simplest method uses the low-order bits of the address shifted right so that the bits that address the byte within the cache line aren’t used. For an 8MB cache with 131,072 64-byte lines that’s:
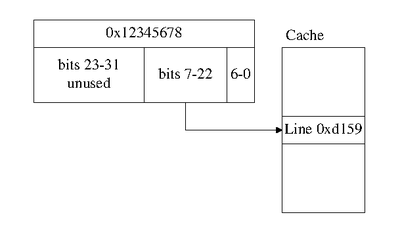
line = (address >> 6) & 0x1FFFFThen the CPU compares that line’s address to the address for the memory request. This means that the cache must store the addresses for each cache line, but in case of my i7 it can skip the 6 lowest bits since that’s how it’s aligned. And also skip the 29 highest bits, because my i7 has only a 39-bit physical address space despite a 48-bit virtual address space and 64-bit general purpose registers. Leaving only 30 bits of the cache line’s address that need to be stored, less than half!
Anyway, if that matches then the cache lookup is a hit and the cache elides (FIRST TIME I used that word) the memory access. If it doesn’t match then the lookup is a miss.
In this scheme every physical address maps to exactly one cache line. To improve the cache’s hit rate we can increase this.
Now we change the equation above to calculate the "set", we also take a bit of precision away - there are half as many sets as there are cache lines.
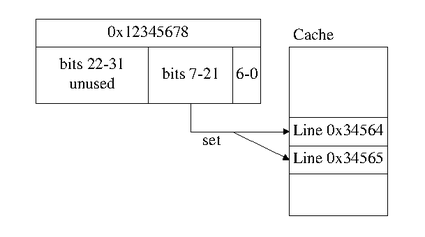
set = (address >> 6) & 0xFFFFEach set in this example has two cache lines in it, the memory we’re looking up can be cached in either; the cache system will check both. This is a 2-way set associative cache. My i7 has a 16-way level 3 cache (the cpuid program on Linux will tell you).
This improves the hit rate, because if two addresses would have been stored in the same cache line, and accessing one may have evicted the other, even if it was recently used and going to be used again. However with an associative cache these collisions don’t lead to evictions as often. The CPU will use an "eviction policy" to decide which line within a set will be evicted.
It’s also possible to have a fully-associative cache, where any memory address can be stored in any cache line.
Inclusive or exclusive cache
If some data is present in the level 2 cache then is it required/expected to be present in L3?
-
Yes: the L3 cache is inclusive
-
No: the L3 cache is not inclusive
Harold reminded me about Victim Caches, which is related to inclusive/exclusive. L2 is a victim cache if when something is evicted from L1 it is then stored in L2. Lines arn’t usually stored in L2 due to misses there.
Write-back vs write-through
When some data is written to that address, and it is cached, will it be written out to to memory/the next cache level immediately?
-
Yes: Write-through
-
No: Write-back
I’ve never knowingly seen a write-through CPU cache, I’ve usually heard this term for disk caches. But there’s a chance I’m wrong and write-through is useful for CPU caches for memory regions that map hardware.
Mike remembers seeing configuration for write-through/write-back in a recent system’s BIOS. I have vague memories of this from a long time ago, memories I didn’t trust to be accuruate enough to report. Maybe it’s true, or maybe we both saw an option for disk cache.
Multiprocessor behaviour
Here’s where things get complicated. Let’s forget my i7, or at least forget the L1 and L3 from my i7.
Processor A reads memory location 5 into its cache (let’s assume it initially contains the value 3), modifies it and the result (4) is stored in Processor A’s write-back cache.
// ptr points to memory location 5,
int *ptr = 5;
// read and update
*ptr = *ptr + 1;Now processor B wants to read the same memory location:
// ptr points to memory location 5,
int *ptr = 5;
printf("The number is %d\n", *ptr);Does B see the number 3, or the number 4. We’re assuming that B runs after A. But even so there’s a good chance B will report "3". That’s because the "4" is in A’s cache.
To solve this we need some system of cache coherence which is almost always combined with some atomic operations and/or fences so that the processors can opt-in to ensuring that things are coherent. They don’t do it all the time because that would be slower / take more energy.
If A uses atomic instructions to read and update memory location 5. When B reads it, then depending on what kind of cache-coherence protocol is used either:
-
The correct value (4) can be read from main memory because A flushed it there and invalidated anyone else’s copy. So B knows it must read it from main memory.
-
The correct value might or might not be in main memory, but B knows that A has a valid copy.
-
B already knows the correct value, because it saw it go by on the memory bus when A wrote it, so it stored it in its own cache then (snooping).
There are more variations, and the 3rd option isn’t the only option for snooping. For example snooping might have noticed that A updated the value but B recorded only that its own value (if it had one) is invalid, and didn’t record the new one. Or only records values that look "interesting" according to some heuristic.
This is a very brief overview. What I really want to share here is that cache coherency is a thing that exists. It’s also one of the reasons why it’s difficult to scale up CPUs to many dozens of cores: the access to memory and coherency is a place where they must coordinate. Alternatives do exist, including NUMA (systems where each processor or small group of processors has its own memory) which may communicate between memories via other (often slower) means.
Memory barriers/fences
Above we introduced atomic instructions, these work well when operating on a single memory location. When more than one location is involved fences are often required. Let’s imagine we have a buffer that two processors use to communicate, this buffer might be used by something like a channel in the Go language.
// Write a value into the buffer
buffer[pos] = new_value;
pos++;The write into the buffer and the write to the current buffer position are likely to both be cached. But what if the update to the position (pos) is flushed or evicted from the processors cache before the change to the buffer itself? Then another processor reading the buffer might read an invalid or incomplete item. What we need is a memory barrier (aka memory fence)
// Write a value into the buffer
buffer[pos] = new_value;
sfence();
pos++;This store fence (an x86 instruction) tells the CPU that all the stores must be visible to other processors before any of the stores that follow. It ensures that the buffer’s contents are ready before the position is updated.
Provided there’s only one thread allowed to update pos then this code is now thread-safe.
There are also other types of fences and atomic instructions, providing various levels of strength. Each architecture is different.
False sharing
When two unrelated things are used by different processors but stored in the same cache line this can lead to a lot of thrashing as the cache system tries to keep a coherent view of this busy cache line. This is known as false sharing. Normally unrelated things end up on different cache lines, but that’s not always true and sometimes they do appear on the same cache line. If that happens try to add padding or otherwise arrange for them to be allocated separately.
Other cache types
CPUs have other things that are either types of cache or things that just "use" cache.
μOP cache
Some more recent Intel CPUs use a μOP cache (micro-operation cache). This is like the L1 instruction cache and stores pre-decoded instructions. It’s good for accelerating short loops and avoids the need to re-decode instructions in these loops (but the loops have to be sufficiently short).
Page translation and TLBs
Translate look-aside buffers (TLBs) may be even more significant than cache. Memory addresses used by your program are known as virtual addresses. These must be translated into physical addresses before they can be retrieved, which is known as page address translation, or just translation.
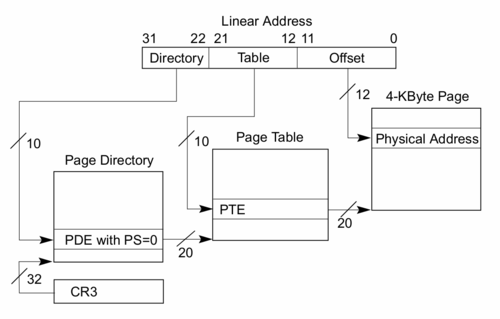
The operating system is responsible for maintaining page tables (structures in memory) that tell the CPU what the physical address for a given virtual address is. In the figure these are shown as the page directory and page table. However since these tables are stored in memory to look them up requires memory accesses (two in the example shown). This could be quite painful, so the CPU will cache the results of these lookups in a special case known as a translate look aside buffer (TLB).
Here’s what my i7 says about its L2 TLB (it also has L1 TLBs but they’re more complex.
0xc1: L2 TLB: 4K/2M pages, 8-way, 1024 entriesPage translation is based around memory pages. Like cache lines, pages break the memory into pieces that get handled in a similar way. x86 pages are normally 4KB, more recent CPUs can support larger pages (we’ll see why in a moment). My L2 TLB for 4K or 2M pages stores 1024 entries and is 8-way associative.
With 1024 entries for typical 4K pages, this can cache page lookups for 4MB of memory. With 2MB pages this increases to 8GB. However I think operating systems and possibly even the CPU tend to prefer 4K pages.
My CPU also supports 4MB and 1GB pages, the former has a TLB at L1 for data only and the latter at L1 for instructions only.
Branch predictor
A modern CPU does its work in a pipeline. While some instructions are being executed or having their results stored, others will be being fetched and decoded. Keeping this pipeline full keeps performance up. One thing that can cause the pipeline to stall is conditional or indirect branch instructions.
In the case of conditional instructions usually some computation is needed to determine whether the branch will be taken. This computation will still be in progress at the time the CPU will want to start fetching instructions and keeping the pipeline full. The CPU will make a guess about the branch and execute instructions tentatively, not storing their results until it knows if the branch will definitely be taken/not-taken.
If it guesses correctly then everything is good and the tentative instructions can retire. If it guesses incorrectly the pipeline must be flushed and refilled with the correct instructions. This can create a significant delay so it’s important to guess accurately.
A simple and reasonable branch predictor (modern CPUs probably use something much more complex) can be implemented with a single bit for every entry. The CPU will take the low bits of the current program counter (aka instruction pointer) and use this to index into a table of entries where it stored the result of the last branch that matched this entry. If that entry is a 1 then the branch was taken last time and will probably be taken this time, if it was 0 then the branch was not taken. When a branch instruction is retired then the "takenness" is stored in the matching entry.
This is similar to looking up the cache line or set for a memory access. Where it’s different is that collisions don’t matter, they only result in an incorrect prediction which may slow down the program, not an incorrect result.
A more advanced version might have N bits per entry, storing the most recent N results of the matching branches and perform some computation such as if there are more 1s than 0s to determine if the branch is likely to be taken again.
Shadow stack
x86 and x86_64 use call and ret instructions to implement a call stack. They’re not necessary as the sp/esp/rsp register can be manipulated directly, but they’re the typical instructions that compilers generate for procedure calls.
Modern x86/x86_64 chips accelerate them by buffering the values pushed on the stack by the call instruction and using this buffer to accelerate ret instructions. It is more of a buffer than a cache, but I wanted to include it anyway. If call and ret instructions become misaligned or the buffer under/overflows than a more general slow-path is used, so it’s not something the programmer or even the operating system needs to manage. It is something that you might wish to be aware of when optimising code though.
Remarks
I wanted to provide a breadth of information about CPU caches. If you want to go deeper on any particular topic I’m sure a web search will point you in the right direction, but hopefully I’ve collected a reasonable overview here.
Next time you hit a performance problem and you want to say "Oh probably cache" and dismiss the artifact, you now have a few clues for deeper investigation. One case where this came up was for the Mercury team (but before I joined the Mercury project). They improved Mercury's performance by ensuring that a bunch of memory regions were not aligned. With paged-aligned regions the commonly used addresses (near the bottom of each region) mapped to the same cache line or set and conflicted with each other. By randomising their alignment the team avoided this conflict and improved performance.
If you liked this article you might also like: x86 Addressing Under the Hood.